先日の Nutanix Meetup Hybrid 24.04 にて、GPT-in-a-Box と、GitHub で公開されている ドキュメント、デモ アプリについて紹介しました。その際の発表資料です。
今回の内容です。
- 当日の録画
- GPT-in-a-Box 入門
- GPT-in-a-Box のドキュメント
- GPT-in-a-Box のデモ アプリ
- GPU と Nutanix HCI
- デモ アプリ利用までの様子(VM を使う パターン)
- 参考: GPU-Operator のインストール方法
- おまけ
当日の録画
当日の録画はこちら・・・
GPT-in-a-Box 入門
今回の Meetup は「Nutanix(再)入門」がテーマだったので、GPT-in-a-Box 入門のスライドです。
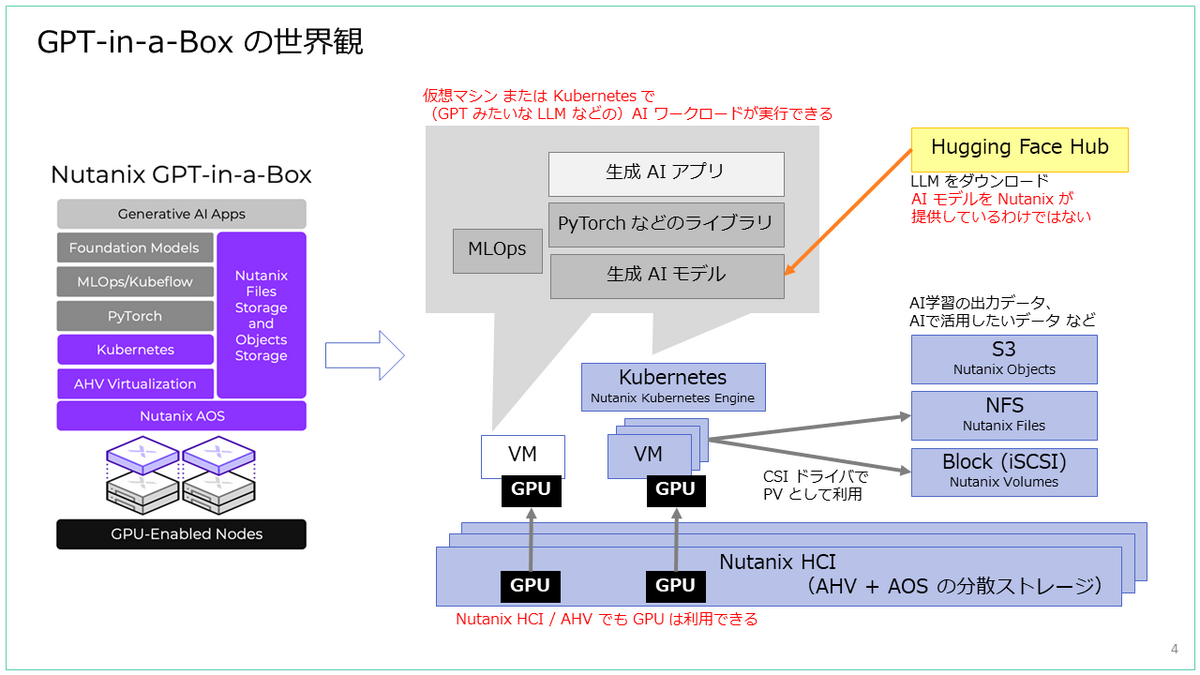
GPT-in-a-Box のドキュメント
ドキュメントでは、仮想マシン(VM)を使うパターンと、Kubernetes を使うパターンが紹介されています。

そして、ドキュメント自体とデモ アプリは、すべて GitHub で公開されています。
- VM を使うパターン
https://github.com/nutanix/nai-llm - Kubernetes を使うパターン
https://github.com/nutanix/nai-llm-k8s
ドキュメントの Overview では、GPT-in-a-Box ソリューションに含まれるものとして下記のように紹介されていますが、一部は今後提供される予定のようです。
- Nutanix Cloud Platform
- GPU に対応できる。仮想化されたコンピューティング、ストレージ、ネットワーキングのシームレスな拡張ができるインフラで、仮想マシンとKubernetesでのコンテナが利用できる。
- Nutanix Files と Nutanix Objects
- 選択した GPT モデルのファイン チューニングや実行でも活用できる。
- AI ワークロードをデプロイおよび実行するためのオープンソースソフトウェア
- 拡張されたターミナル UI または標準 CLI のための管理インターフェース
- 厳選された LLM のサポート
- Llama2、Falcon、MPT を含む(Hugging Face Hub からダウンロード)
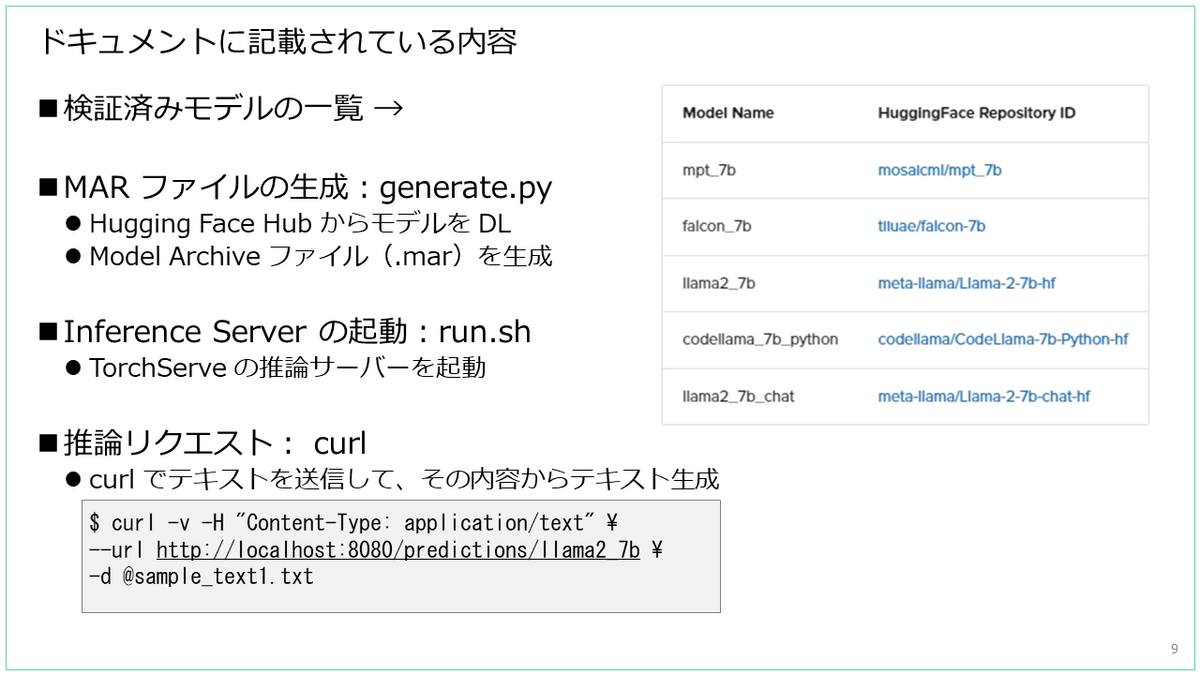
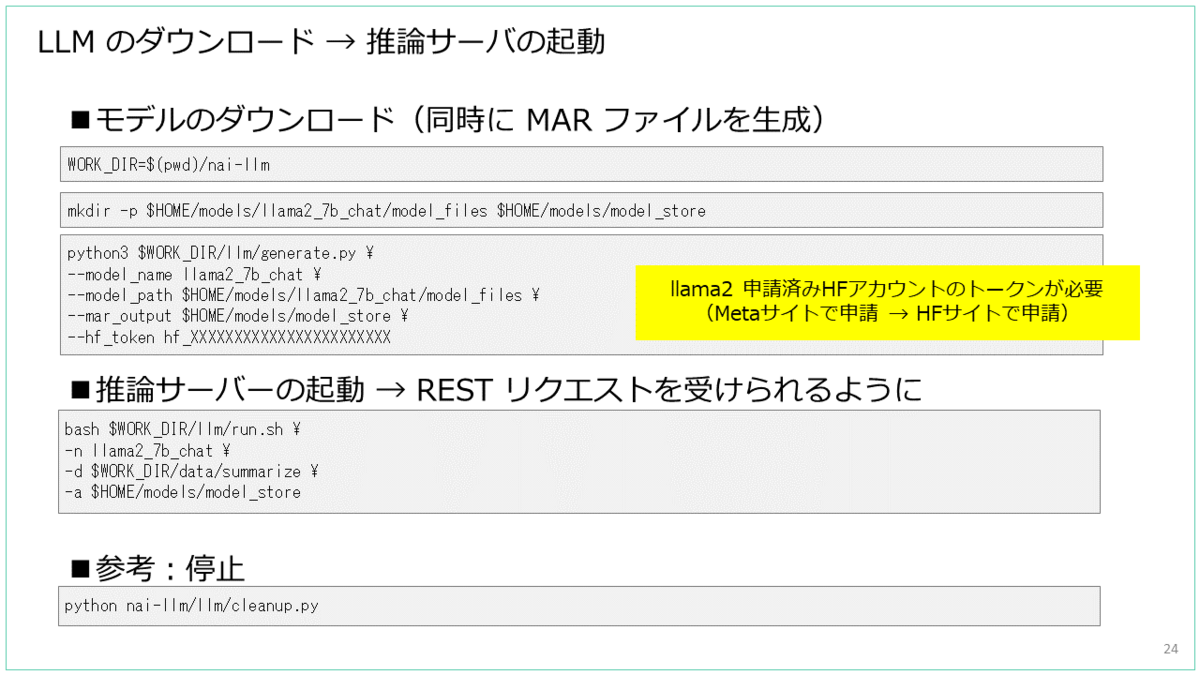
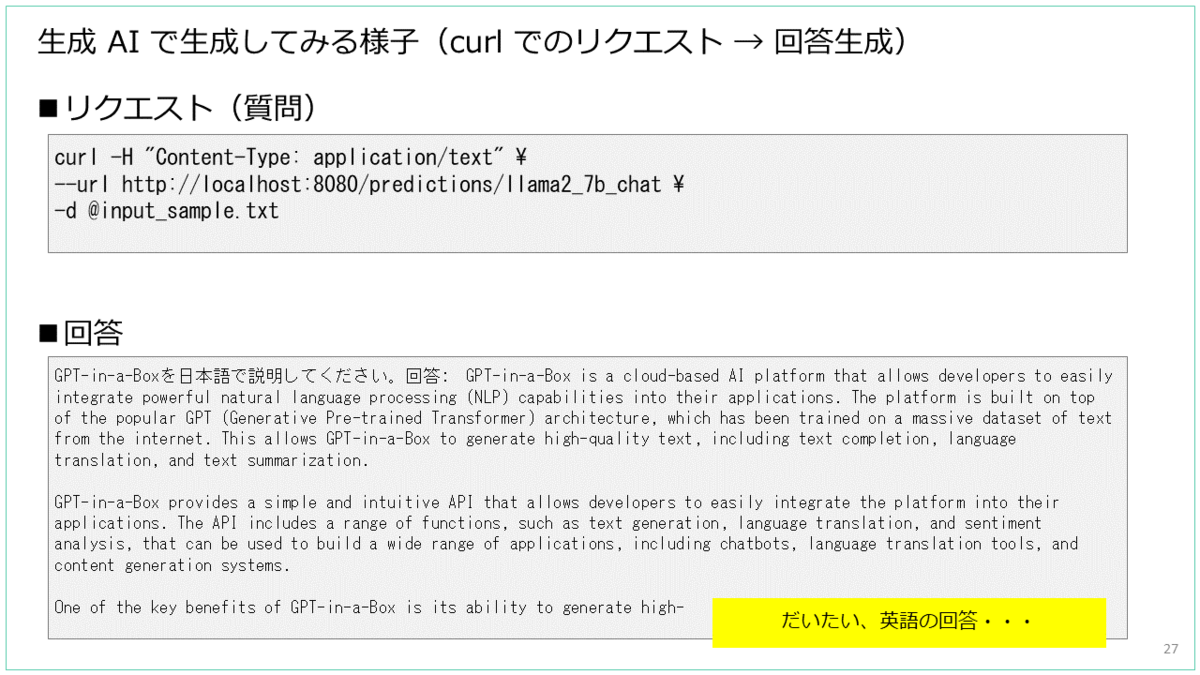
ドキュメントでは、検証済みモデルの説明から、推論サーバを起動して curl によるリクエストでテキストを生成するところまでが説明されています。
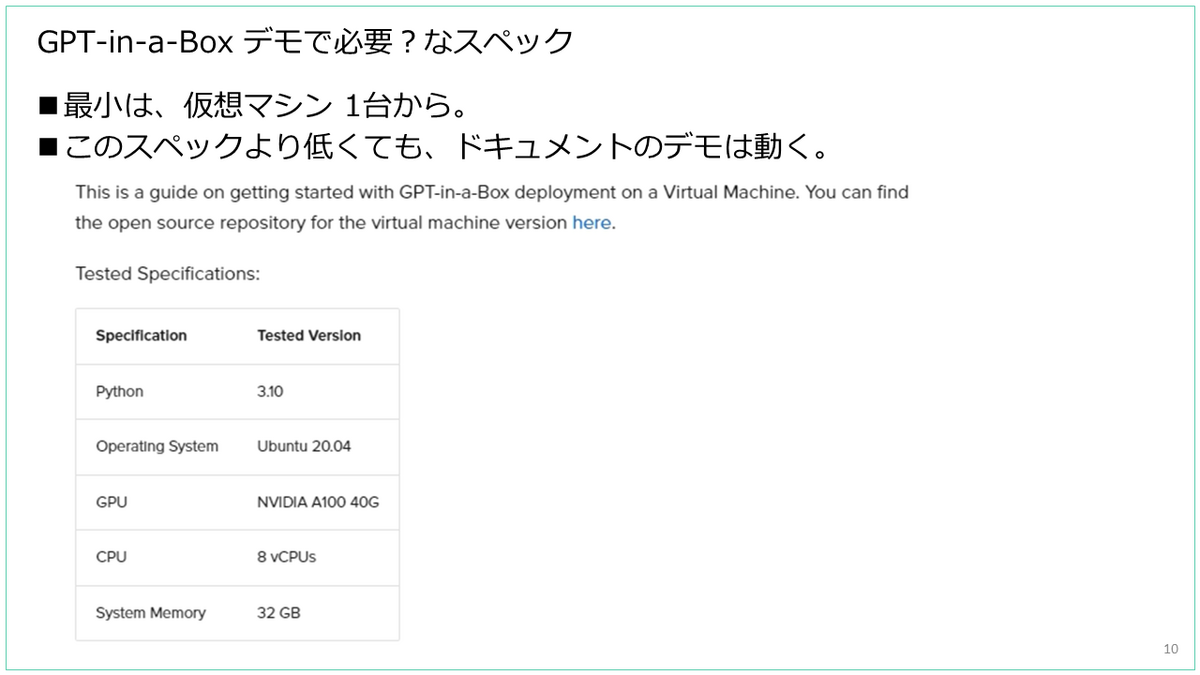
VM を使うパターンで試す場合には、1台の VM だけでも始められます。
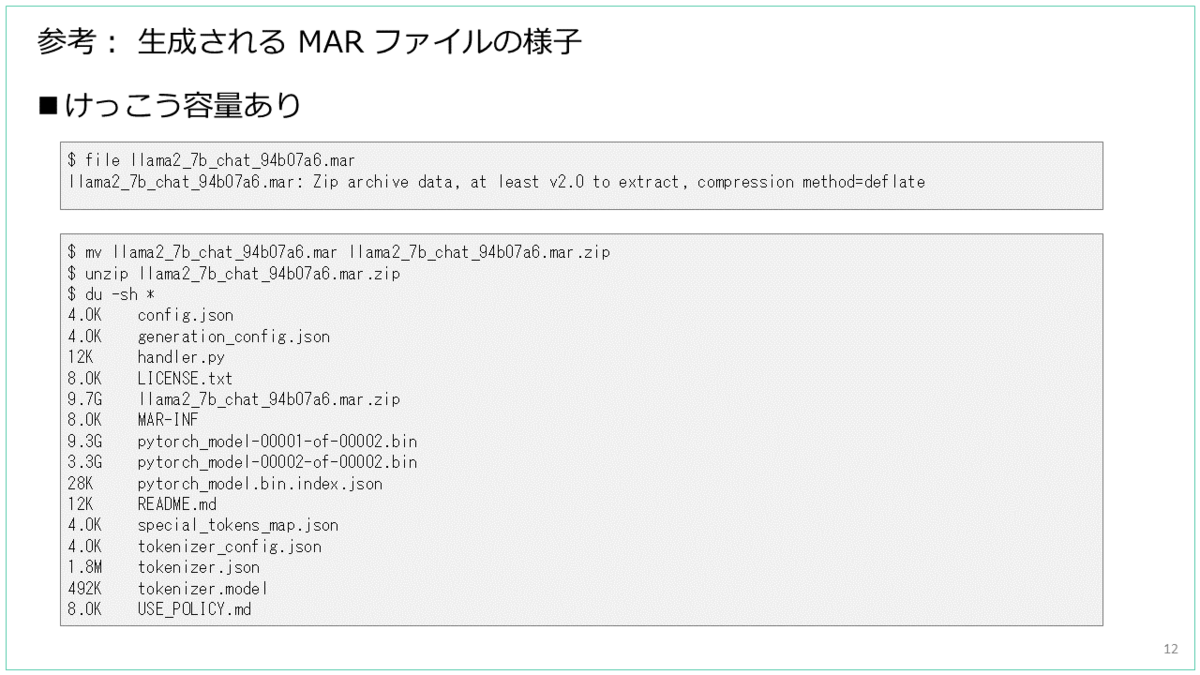
ダウンロード → MAR 形式で保存したモデルのサイズ感です。

MAR ファイルは、zip 形式で下記のようなファイル一式がアーカイブされたものです。
GPT-in-a-Box のデモ アプリ
デモ アプリのチャット ボットに関連するファイルは、VM / Kubernetes を使うパターンのそれぞれの GitHub リポジトリ直下の、demo ディレクトリに格納されています。

チャットボットは、Hugging Face Space などでおなじみ? の、Streamlit で作成されています。

ドキュメントの手順にしたがって起動した推論サーバーに curl でリクエストする代わりに、このチャットボットの Web UI が利用できるようになります。 (手順の様子はのちほど)

GPU と Nutanix HCI
Nutanix HCI の AHV や NKE で GPU を利用する際のイメージも紹介しておきます。
生成 AI などで GPU の性能を最大限活用する際には、vGPU よりも GPU パススルー接続になりそうなので、今回は基本的に GPU パススルー接続の話です。
AHV 上の仮想マシンでパススルー接続による GPU を利用する場合には、ベアメタル サーバーの OS で利用する場合と同様に、ゲスト OS に GPU ドライバのインストールが必要です。
NKE によるコンテナ ホストで GPU を利用する場合は、Kubernetes クラスタに、GPU ドライバが含まれる「GPU-Operetaor」をインストールします。
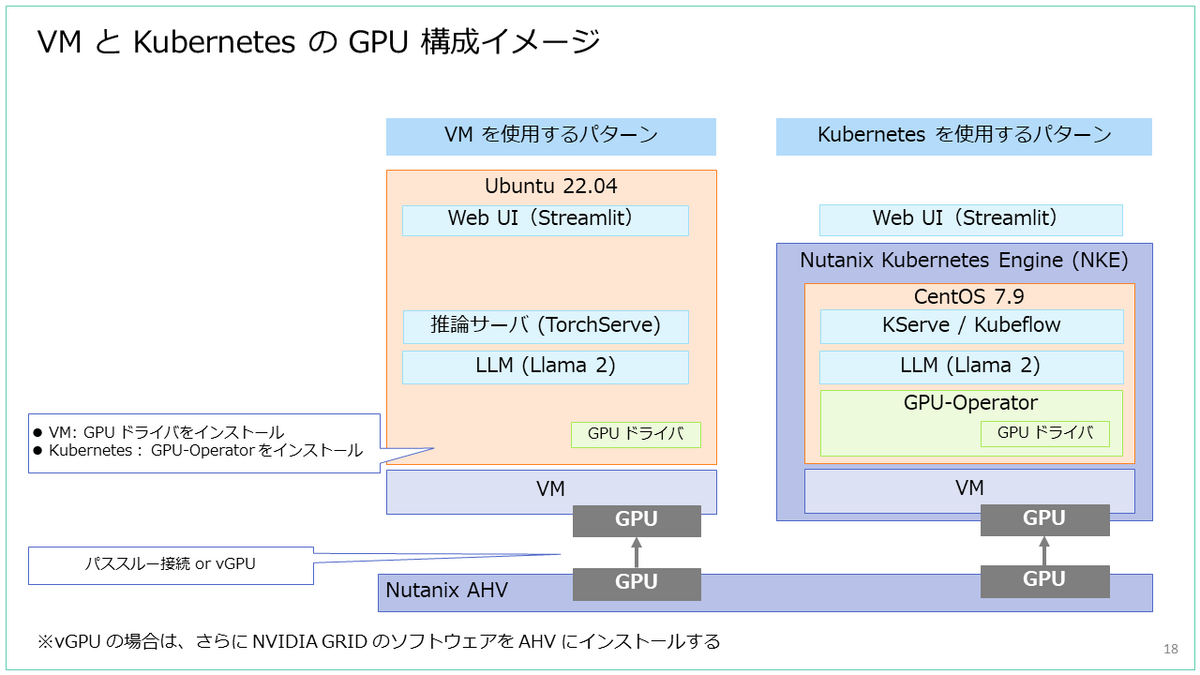
NKE で GPU 搭載の Kubernetes クラスタを利用したい場合は、NKE で Kubernetes クラスタを作成したあとに、さらに「GPU ノード プール」を追加することで、アプリを展開するワーカー ノードを追加します。

Kubernetes を使うパターンのデモでは、Nutanix Files による NFS サーバーを Kubernetes の PV として利用します。
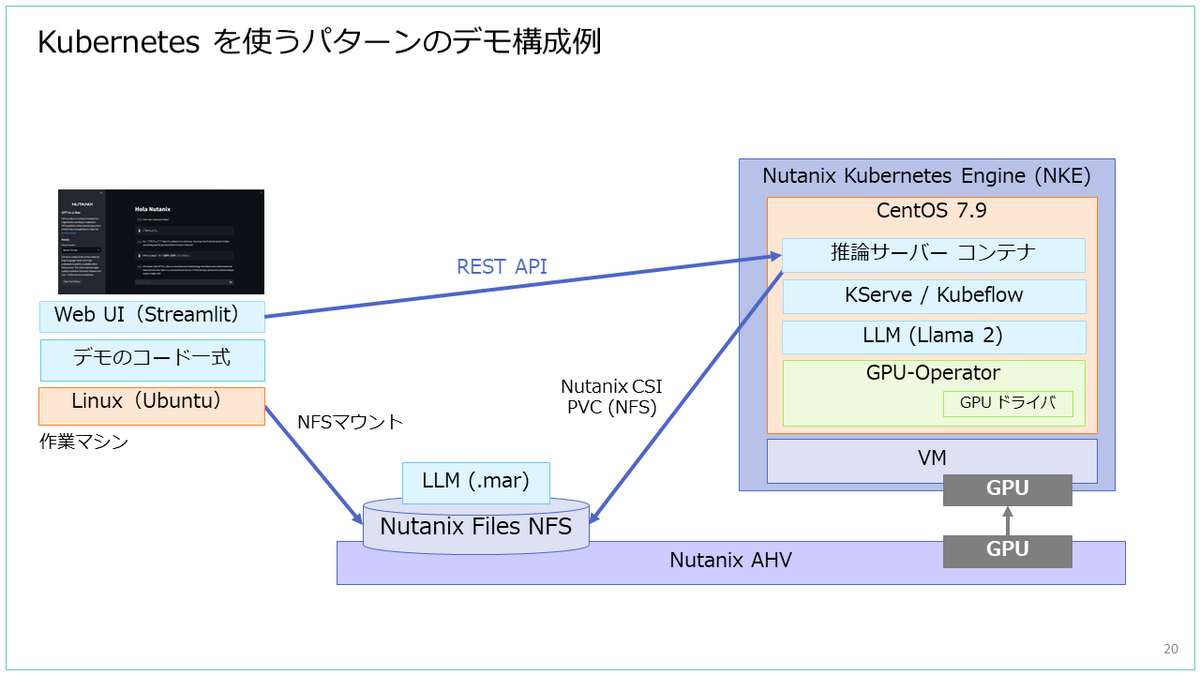
デモ アプリ利用までの様子(VM を使う パターン)
さいごに、でもアプリ利用までの様子を簡単に紹介します。




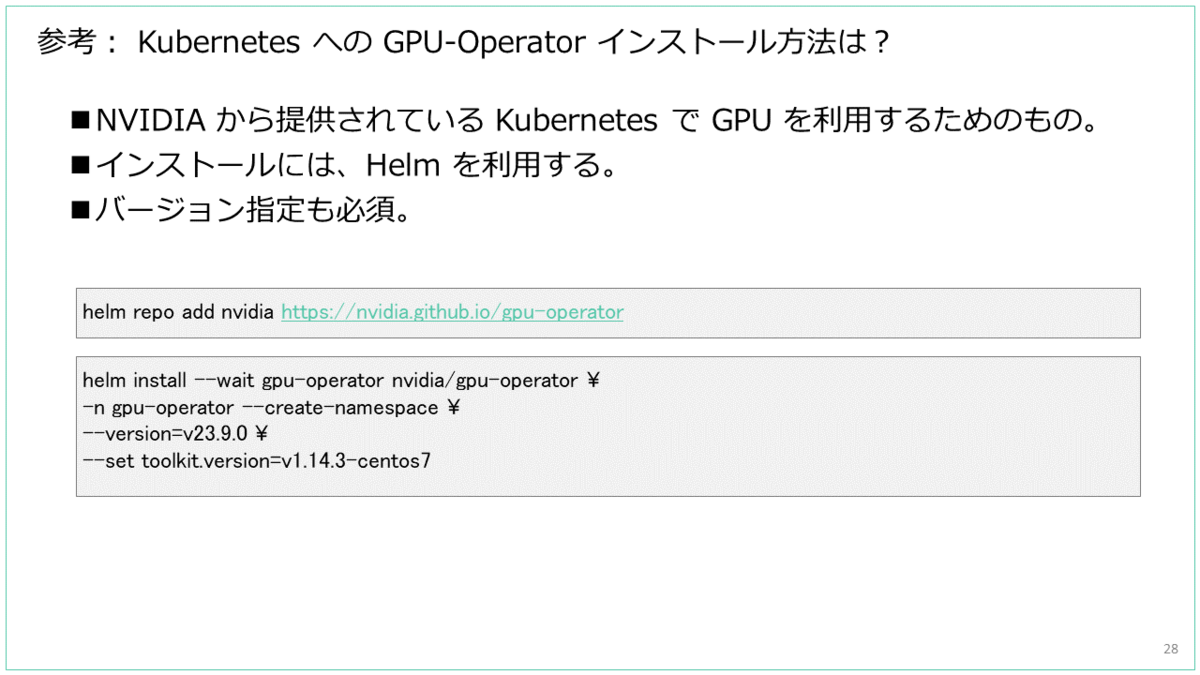
参考: GPU-Operator のインストール方法
GPU-Operetaor は、NVIDIA から提供されている Kubernetes で GPU を利用するためのもので、インストールには Helm を利用します。
NKE にインストールする場合は、OS イメージが CentOS 7 ベースなこともあり、下記のようにバージョン指定が必須となります。
GPT-in-a-Box は、Nutanix AHV で稼働する仮想マシンや Kubernetes で GPU を活用できるお墨付き構成のようなソリューションですが、GPT モデルや生成 AI に限らず、AI/ML もろもろで Nutanix を活用する世界観みたいなものと考えるとよいかもしれません。
そして、生成 AI や GPT は大流行中なので、来月の .NEXT でもなにか新発表があることを期待しています・・・
おまけ
ちなみに、GPT-in-a-Box のデモは、じつは CPU でも動作します。ただし、テキスト生成などにはだいぶ時間がかかります。

以上。
