Nutanix Database Service(NDB)で PostgreSQL 15 + pgvector のデータベースをプロビジョニングしてみます。
前回はこちら。
今回の内容です。
- pgvector とは
- 今回の環境
- 1. PostgreSQL DB サーバー VM の用意
- 2. pgvector のインストール
- 3. ソフトウェア プロファイルの作成
- 4. DB のプロビジョニング
- 5. DB への接続と pgvector の動作確認
pgvector とは
PostgreSQL でベクトル データを扱えるようにする拡張機能で、GitHub でオープンソースとして公開されています。
今回の環境
利用するソフトウェアは下記です。
pgvector の最新は v0.7.0 ですが、デフォルトでインストールしたらエラーになったのでひとつ前のバージョンを利用しています。
- Nutanix CE 2.0
- NDB 2.5.4
- Red Hat Enterprise Linux 8.9
- PostgreSQL 15.6
- pgvector 0.6.2
1. PostgreSQL DB サーバー VM の用意
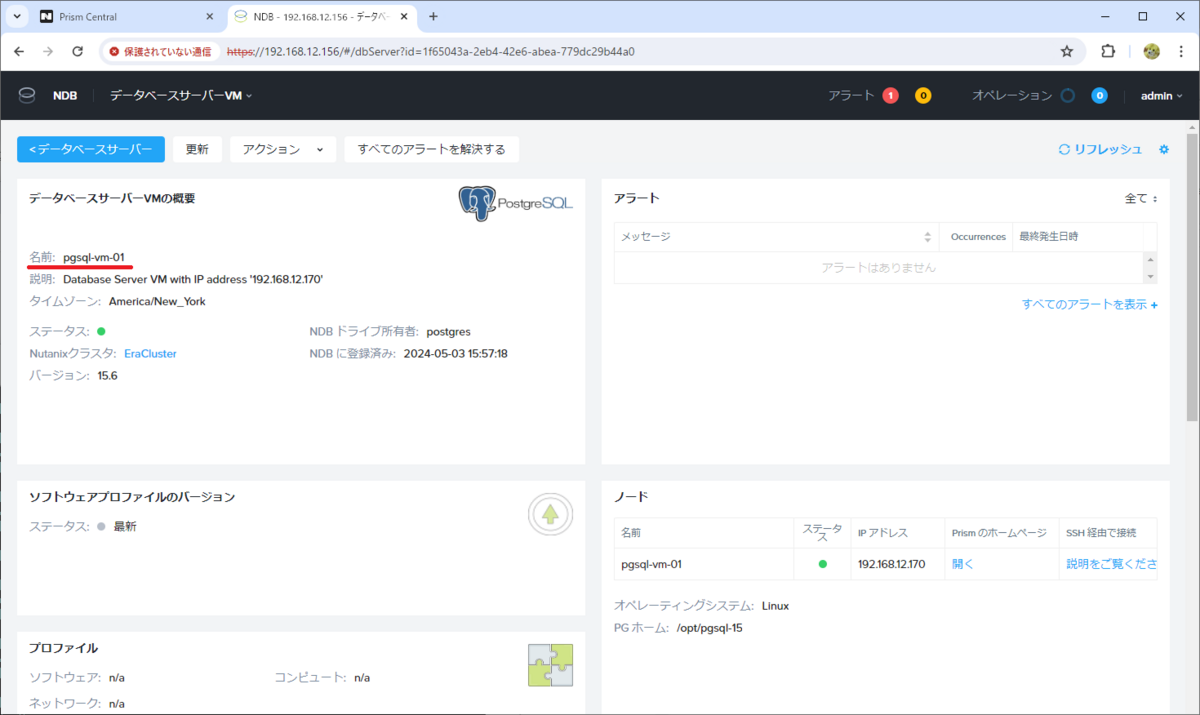
下記の「1. 登録用 DB サーバー VM の構築」までの手順で、PostgreSQL 15.6 をインストールした RHEL 8.0 の DB サーバー VM「pgsql-vm-01」を用意します。
ここから、pgsql-vm-01 に SSH 接続して pgvector をインストールします。
2. pgvector のインストール
2-1. インストールの準備
pgvector のソース コードを入手するために、git をインストールします。
[root@pgsql-vm-01 ~]# dnf install git -y
sudo 実行時の PATH 設定を追加します。
[root@pgsql-vm-01 ~]# echo 'Defaults secure_path = /opt/pgsql-15/bin:/sbin:/bin:/usr/sbin:/usr/bin' >> /etc/sudoers.d/postgres
sudo で pg_config が実行可能になっていることを確認しておきます。
[root@pgsql-vm-01 ~]# su - postgres [postgres@pgsql-vm-01 ~]$ sudo pg_config BINDIR = /opt/pgsql-15/bin DOCDIR = /opt/pgsql-15/share/doc HTMLDIR = /opt/pgsql-15/share/doc INCLUDEDIR = /opt/pgsql-15/include PKGINCLUDEDIR = /opt/pgsql-15/include INCLUDEDIR-SERVER = /opt/pgsql-15/include/server LIBDIR = /opt/pgsql-15/lib PKGLIBDIR = /opt/pgsql-15/lib LOCALEDIR = /opt/pgsql-15/share/locale MANDIR = /opt/pgsql-15/share/man SHAREDIR = /opt/pgsql-15/share SYSCONFDIR = /opt/pgsql-15/etc PGXS = /opt/pgsql-15/lib/pgxs/src/makefiles/pgxs.mk CONFIGURE = '--prefix=/opt/pgsql-15' CC = gcc CPPFLAGS = -D_GNU_SOURCE CFLAGS = -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wcast-function-type -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -Wno-stringop-truncation -O2 CFLAGS_SL = -fPIC LDFLAGS = -Wl,--as-needed -Wl,-rpath,'/opt/pgsql-15/lib',--enable-new-dtags LDFLAGS_EX = LDFLAGS_SL = LIBS = -lpgcommon -lpgport -lz -lreadline -lpthread -lrt -ldl -lm VERSION = PostgreSQL 15.6
2-2. pgvector のインストール
ここからは、postgres ユーザで作業します。PostgreSQL インストール先(PG_HOME。今回は /opt/pgsql-15)の直下にある bin ディレクトリを PATH 環境変数に追加します。
[postgres@pgsql-vm-01 ~]$ export PATH=/opt/pgsql-15/bin:$PATH
psql が実行できるようになっていることを確認します。
[postgres@pgsql-vm-01 ~]$ psql --version psql (PostgreSQL) 15.6
pgvector 0.6.2 をダウンロードします。
[postgres@pgsql-vm-01 ~]$ git clone --branch v0.6.2 https://github.com/pgvector/pgvector.git Cloning into 'pgvector'... remote: Enumerating objects: 9451, done. remote: Counting objects: 100% (2966/2966), done. remote: Compressing objects: 100% (585/585), done. remote: Total 9451 (delta 2464), reused 2494 (delta 2375), pack-reused 6485 Receiving objects: 100% (9451/9451), 1.40 MiB | 8.56 MiB/s, done. Resolving deltas: 100% (7028/7028), done. Note: switching to '96ff19be4487a843fa96f8801afcfdd49ac3eeac'. You are in 'detached HEAD' state. You can look around, make experimental changes and commit them, and you can discard any commits you make in this state without impacting any branches by switching back to a branch. If you want to create a new branch to retain commits you create, you may do so (now or later) by using -c with the switch command. Example: git switch -cOr undo this operation with: git switch - Turn off this advice by setting config variable advice.detachedHead to false [postgres@pgsql-vm-01 ~]$
pgvector ディレクトリに移動します。
[postgres@pgsql-vm-01 ~]$ cd pgvector/
make コマンドを実行します。
[postgres@pgsql-vm-01 pgvector]$ make
make install を実行すると、PG_HOME 配下に pgvector 関連のファイルがインストールされます。
[postgres@pgsql-vm-01 pgvector]$ sudo make install
2-3. NDB の Post Script の配置
ソフトウェア プロファイルを作成する前に、NDB での DB プロビジョニング直後に pgvector を有効化する Bash スクリプトを配置しておきます。
これは CREATE EXTENSION を実行するだけなので、Post Script なしでプロビジョニングして、初回接続時に「CREATE EXTENSION vector;」コマンドを実行してもかまいません。
create-extension-pgvector.sh
- L2: スクリプト動作確認のため、数カ所で $HOME/post_script.log ファイルに出力をリダイレクト。
- L3: PG~といった環境変数を読み込むために、.bash_profile を読み込む。.bash_profile の環境変数は、プロビジョニング中に NDB が追記している。
- L8: pg_hba.conf に、postgres ユーザのパスワードなしログインのための設定を追記。
- L9: PostgreSQL のサービスを再起動。
- L10: サービス再起動の直後に psql を実行するとエラーになるので 10秒待機。
- L16: pgvector を有効化。ここで DB 名を指定しているので、DB プロビジョニング時に作成する初期 DB の名前も「vectordb」にする。
- L18: Post Script がなぜかエラー終了するので、やむなく exit 0
このスクリプトは /home/postgres/create-extension-pgvector.sh として保存して、実行権限を付与(chmod +x)しておきます。
[postgres@pgsql-vm-01 ~]$ chmod +x create-extension-pgvector.sh [postgres@pgsql-vm-01 ~]$ ls -l /home/postgres/create-extension-pgvector.sh -rwxrwxr-x 1 postgres postgres 554 5月 5 10:11 /home/postgres/create-extension-pgvector.sh
3. ソフトウェア プロファイルの作成
pgvector をインストールした DB サーバ VM(pgsql-vm-01)は、前回の投稿で NDB に登録 されています。
そこで、前回の「3. ソフトウェア プロファイルの作成」と同様の手順でソフトウェア プロフィアルを作成します。
今回は、下記のパラメータでプロファイルを作成します。
- プロファイル名: postgres-15.6-pgvector
- ソフトウェア プロファイル バージョンの名前: postgres-15.6-pgvector (1.0) ※自動入力
- プロファイルで使用するソフトウェアを持つデータベース サーバーの選択: pgsql-vm-01
- プロファイルを作成したら、ソフトウェア プロファイル バージョン「postgres-15.6-pgvector (1.0)」を「公開」しておく。

4. DB のプロビジョニング
DB サーバー VM と、DB をプロビジョニングします。
NDB Server で「データベース」→「ソース」を開き、「プロビジョン」→「PostgreSQL」→「インスタンス」をクリックします。

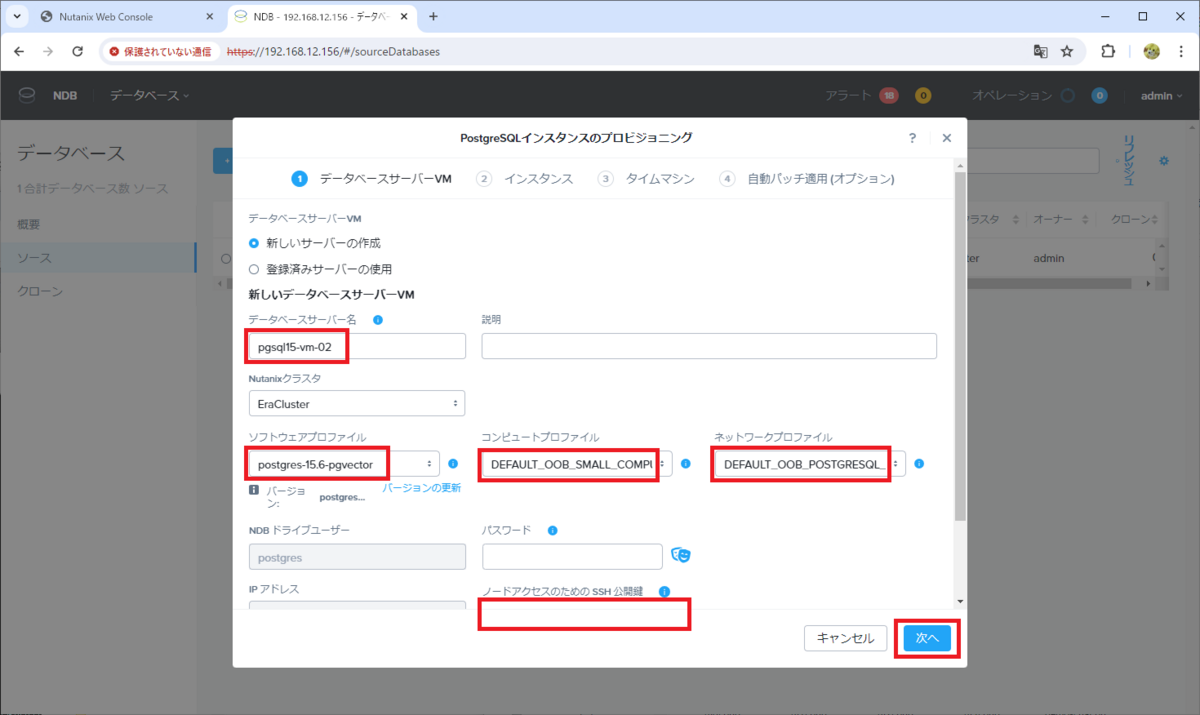
「データベース サーバー VM」画面で、下記を入力して画面をスクロールします。前回との差分は、赤字にしています。
- データベース サーバー VM: 新しいサーバーの作成 ※デフォルトのまま
- データベース サーバー名: pgsql15-vm-02
- ソフトウェア プロファイル: postgres-15.6-pgvector
- コンピュート プロファイル: DEFAULT_OOB_SMALL_COMPUTE
- ネットワーク プロファイル: DEFAULT_OOB_POSTGRESQL
- ノードアクセスのための SSH 公開鍵: postgres ユーザで SSH ログインするための SSH 公開鍵を「テキスト」欄に入力
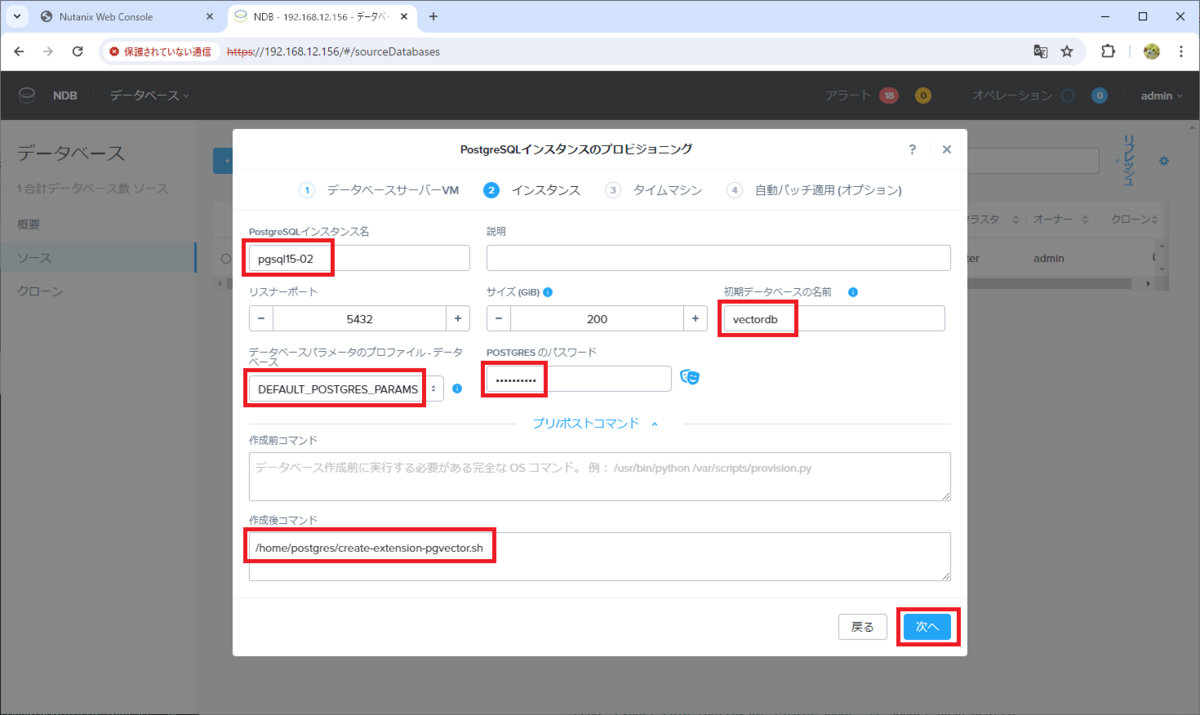
DB インスタンスの情報を入力して「次へ」をクリックします。
- PostgreSQL インスタンス名: pgsql15-02
- リスナー ポート: 5432 ※デフォルトのまま
- サイズ (GiB): 200 ※デフォルトのまま
- 初期データベースの名前: vectordb
- データベース パラメータのプロファイル - データベース: DEFAULT_POSTGRES_PARAMS
- POSTGRES のパスワード: postgres ユーザに設定するパスワードを入力
- プリ/ポスト コマンド → 作成後コマンド:
/home/postgres/create-extension-pgvector.sh
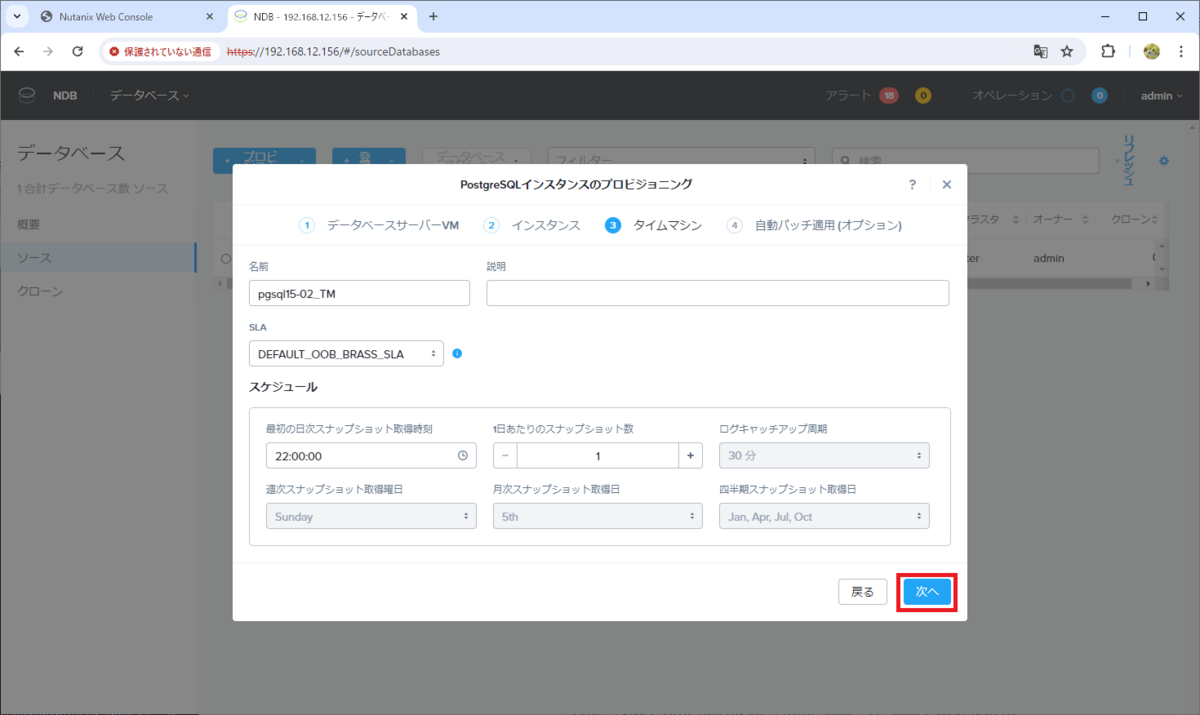
タイムマシンの設定を入力して「次へ」をクリックします。
- 名前:pgsql15-02_TM ※デフォルトのまま
- SLA: DEFAULT_OOB_BRASS_SLA ※デフォルトのまま
「自動パッチ適用」画面では、そのまま「プロビジョン」をクリックします。
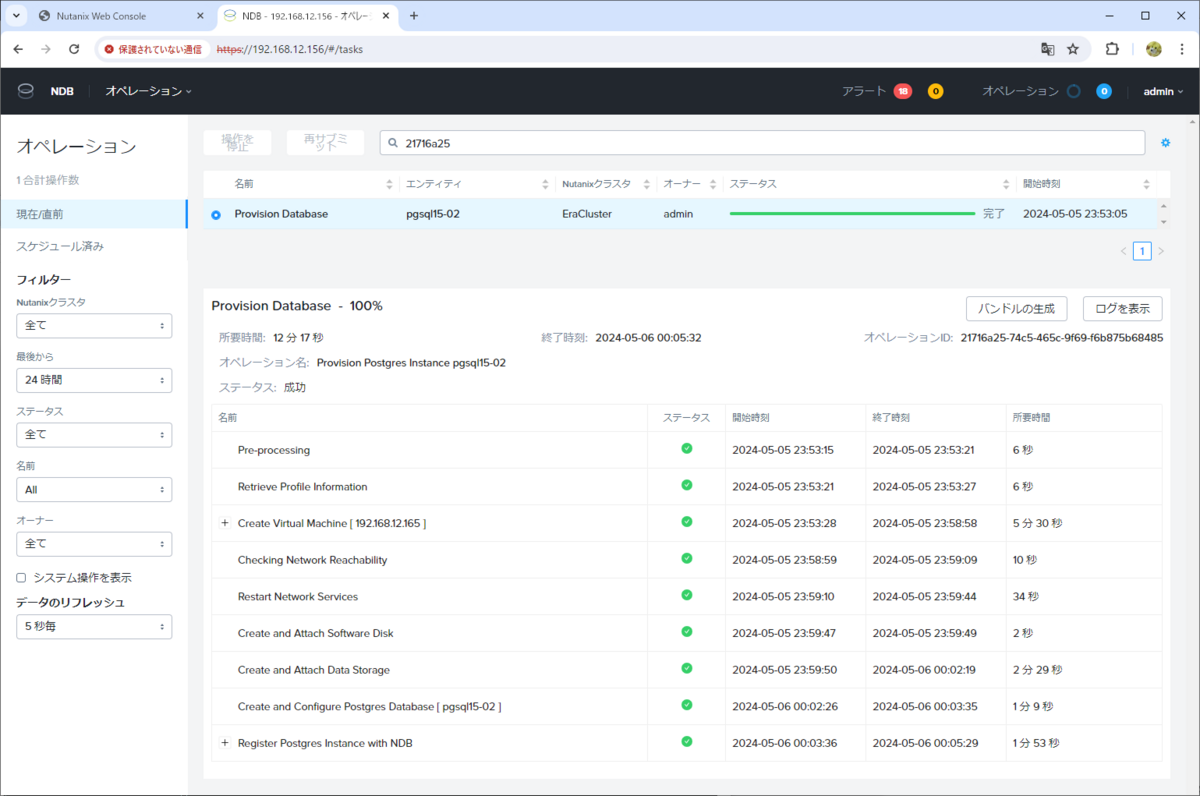
「オペレーション」画面で、進捗を確認できます。しばらく待つと、DB サーバー VM と DB が作成されます。
5. DB への接続と pgvector の動作確認
5-1. DB(vectordb)への接続情報の確認
「データベース」→「ソース」画面を開くと、プロビジョニングされた DB が表示されます。DB の名前をクリックします。
- 名前: pgsql15-02

「pgsql15-02」の画面で、データベース「vectordb」の行にある「説明をご覧ください」をクリックします。
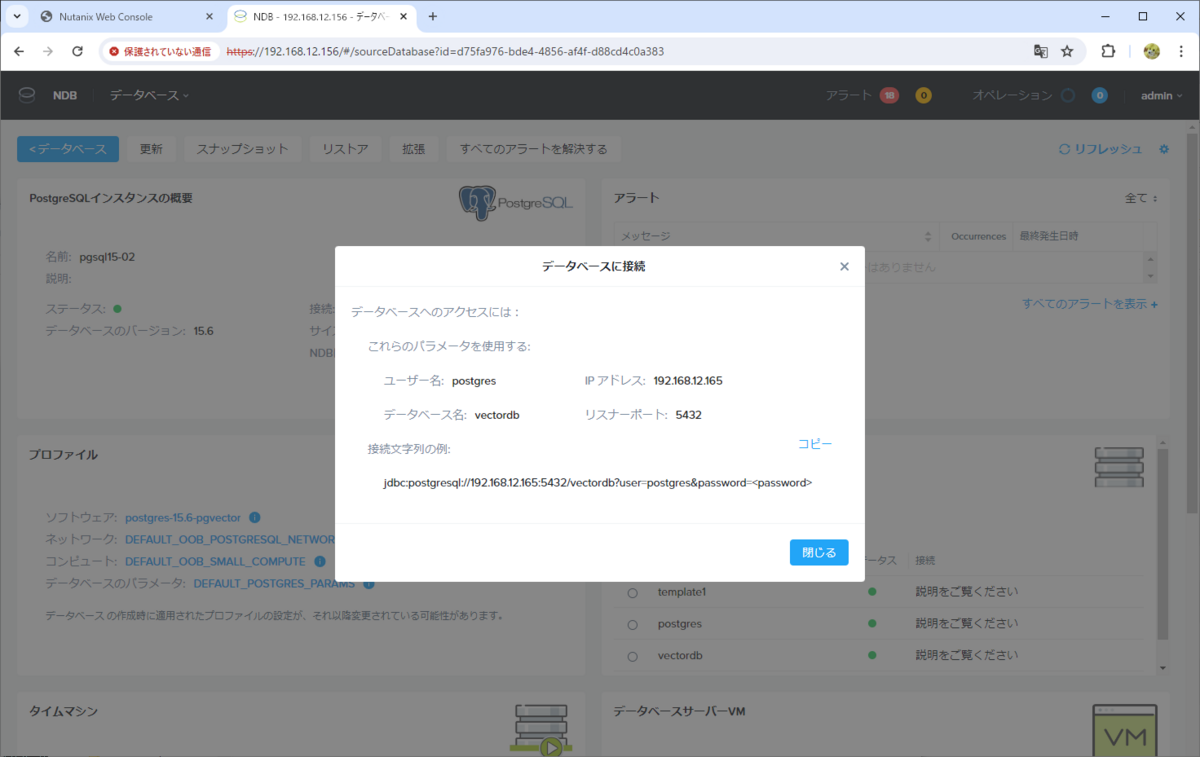
DB への接続情報を確認できます。
5-2. DB への接続(psql)
psql を実行するクライアント マシンとして、前回プロビジョニングした DB サーバ(pgsql15-vm-01)を利用します。
[postgres@pgsql15-vm-01 ~]$ cat /etc/redhat-release Red Hat Enterprise Linux release 8.9 (Ootpa) [postgres@pgsql15-vm-01 ~]$ psql --version psql (PostgreSQL) 15.6
NDB Server で確認した接続情報をもとに、psql で DB に接続します。
- ホストの IP アドレス: 192.168.12.165
- ポート: 5432
- DB: vectordb
- ユーザ: postgres
[postgres@pgsql15-vm-01 ~]$ psql --host=192.168.12.165 --port=5432 --dbname=vectordb --username=postgres Password for user postgres: ★パスワードを入力 psql (15.6) Type "help" for help. vectordb=#
pgvector 0.6.2 がインストールされています。
vectordb=# SELECT extname,extversion FROM pg_extension WHERE extname = 'vector'; extname | extversion ---------+------------ vector | 0.6.2 (1 row)
pgvector の README で紹介されている例をもとに、VECTOR 型のフィールドを持つテーブル(items)を作成します。
vectordb=# CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3)); CREATE TABLE
items テーブルが作成されました。
vectordb=# \d items
Table "public.items"
Column | Type | Collation | Nullable | Default
-----------+-----------+-----------+----------+-----------------------------------
id | bigint | | not null | nextval('items_id_seq'::regclass)
embedding | vector(3) | | |
Indexes:
"items_pkey" PRIMARY KEY, btree (id)
そして、ベクトル データが格納できました。
vectordb=# INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
INSERT 0 2
vectordb=# SELECT * FROM items;
id | embedding
----+-----------
1 | [1,2,3]
2 | [4,5,6]
(2 rows)
以上。
